Indekslenebilir Ajax: HTML Snapshot Oluşturma

Indekslenebilir Ajax
Bu yazıda artık işin iyice mutfağına gireceğiz. Snippet’lerle örnekleyerek ve teorileri artık pratiğe dökerek sonuca gideceğiz.
İlk olarak hash fragment içermeyen sayfalarla crawlerların arasındaki problemi çözelim.
Bazı sayfalarınız hash fragmentler içermiyor olabilir. Örneğin, anasayfanızın www.örnek.com değilde www.örnek.com#!home olmasını isteyebilirsiniz. Bu durum için hash fragment içermeyen sayfalar için yapmamız gerekenler var.
Not: Bu aşağıdaki anlatılanlar sadece ve sadece Ajaxla yaratılmış yani dinamik içerikler için uygun olacaktır. Statik içerik içeren siteler için bu uygulamar crawlera ekstradan bir bilgilendirme sağlayamaz. Tam tersine Google’ın ve kullandığınız servera yük yapar.
Hash fragment içermeyen siteleri indekslenebilir hale getirmek için, sayfanızın HTMLsinin başlık kısmına özel bir meta tag ekliyoruz.
< meta name=”fragment” content=”!” >
Bu crawlera hash fragment içermeyen URLyi indekslemesi gerektiğini belirliyor.
’i www.örnek.com ‘a yerleştirdiğinizde crawler geçici olarak bu URLyi www.example.com?_escaped_fragment_=’e dönüştürüyor ve bu siteyi talep ediyor. www.örnek.com için gerekli olan HTML Snapshot’ı da server bu durumda crawlera gönderme durumunda kalıyor.
Ajax URL’ler için yeni Sitemap hazırlamanız da gerekiyor.
Crawlerlar indekslerken Site haritasına ihtiyaç duyarlar. Yeni site haritanız URLnizin yeni şeklini içine dahil etmiş olması gerekiyor ki arama sonuçlarında ortaya çıkabilsin. https://example.com/ajax.html#!key=value Arama sonuçlarında buna benzer bir şekilde çıkacaktır site URLsi. https://example.com/ajax.html?_escaped_fragment_=key=value böylesi bir URLyi kesinlike Site haritanızda bulundurmayın
HTML Snapshot oluşturma rehberi
Eklentiniz ilk yazımıda bahsettiğimiz HTML Snapshot ve URL haritalaması(hash fragmentle ve fragmentsız arasındaki kısa süreli dönüşümler) yolunu izlediği sürece indekslenebilir olacaktır.
Gerçekten de frameworkler, kütüphaneler vs yaratmanın birçok yolu var. HTML Snapshotlar için de aynısı geçerli. Bunun seçimini, eklentinizin yapısına ve sitenizle kurduğu ilişkiye göre uygun bir şekilde hazırlamak ise esas amacımız olacak bu yazıda.
1. ‘’işe yaramaz’’ Metod, Her dinamik olgu için statik içerik yaratmak.
Web sitesi tasarımcıları dinamik olguları statik içerikte kullanabilmek için HIJAX diye bir yöntemi uzun zamandır kullanıyorlar. Üzerinden şerbeti alınmış baklava neyse, AJAX uygulamalarını bu programın ne hale soktuğunu bu örnekle açıklayabiliriz. Dinamik bir durumu, statik olarak iletilmesini sağlıyor HIJAX. Çok hızlı ve sık güncellenme olmuyorsa sitenizde kullanmaya değer bir metod.
Hijax hibrid bir uygulama, Ajax yine aynı Ajax fakat onun dinamizmine bir sınır getiriyor ve optimizasyon için daha uygun hale getiriyor. Örneğin bir sitenin hyperlinki var. Javascript açıkken, Ajax normalde linkin doğal davranışını ‘hijack’eder(linkin onu nereye nasıl götüreceğinin içinde dolanır ve gerekeni haritalar tüm yolu size gezdirip bir de haritalamaz kısacası. İşlemler daha kısa sürer), -hijack de ismini buradan alıyor- ve bir miktar yeni içeriği yükler. Javascript açık değilken ise tüm sayfayı, yeni veya değil fark etmez tümünü yeniden yükler. Ajax ile yükleme zamanları izlenebilir bir nitelik taşır ve URL kendini yenileyerek, eşzamanlı eklenen içerikler eşzamanlı olarak işlenir.
AJAX URLlerin arama sonuçlarında HTML statik URLler yerine çıkabilmesi için bu uygulama yeterli olmuyor, ve #! AJAX URL yapısını kullanabilmek için ve _escaped_fragment_ taleplerine cevap verebilmek için daha birçok modifikasyona ihtiyaç duyuluyor. Bu en basit, ve en az ‘tatmin’ eden yöntem diyebiliriz.
PHP ve ASP.NET teknolojileri kullanılarak yaratılmış İçerikler için
Daha gelişmiş bir kullanım olanağı sunmak için eklentileriniz AJAX kullanıyor olsa dahi, içeriğinizin büyük bir kısmı server tabanlı teknolojilerle yani PHP veya ASP.NET ile biçimlendiriliyor. İlk yazıdaki filmle ilgili içeriği hatırlayın(kodun içindeki):
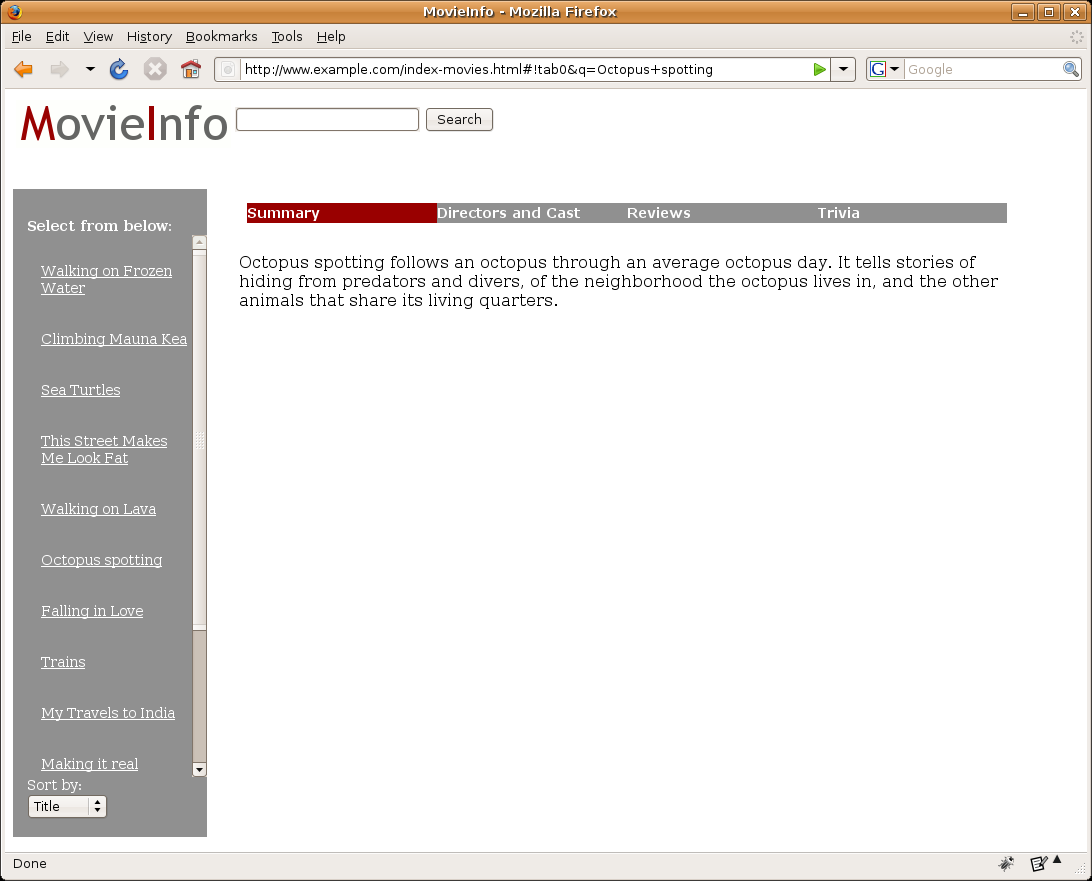
’Octopus spotting follows an octopus through an average octopus day. It tells stories of hiding from predators and divers, of the neighborhood the octopus lives in, and the other animals that share its living quarters.
Görüldüğü üzere URL hash fragment’ler içeriyor , #!tab0&q=Octopus+spotting. Görünenin ardında, aplikasyonunuz javascript hash fragmentleri işliyor ve bir XHR talebinde bulunuyor, ardından da sonuç olarak bir PHP scriptini harekete geçiriyor. PHP scripti ardından görülür haldeki içeriklerde arama yapıyor, tam bir yenilemeye gitmeden HTMLyi yaratıp siteye ekliyor. Örneğin Jquery kullanıyorsanız, hash fragmenti ayırdıktan sonra XHR talebini gönderebilirsiniz:
function getResults(params, urlToGet) {
// urlToGet will be something like getdata.php?tab=tab0&q=Octopus+spotting
$.ajax({
type: "POST",
url: urlToGet,
dataType: "json",
success: function(msg){
updatePage(params, msg);
}
});
}
Bu durumda, içeriğinizi taşıyan HTML dinamik bir şekilde serverda değilde, serverda yaratılmış olduğundan hala crawlerlar için görünmez olacaktır. Çünkü dinamik olarak eklendi… bir hash fragmente bağlı olarak, XHR kullanarak. Peki bunu AJAX indeksleme şekillerinden birine nasıl uyduracağız? Yine ve yine, aplikasyonunuzun hash fragment talebinde bulunulduğunda bir HTML snapshot oluşturması gerektiğini, bunun da bir _escaped_fragment_ ismiyle bulunan bir sorgu parametresi olduğunu hatırlatmış olalım. Bunu bir scriptle de yapabilirsiniz, gethtmlsnapshot.php scripti gibi örneğin, daha önceden hazırlanmış PHP scriptleri kullanarak(getdata.php) snapshot yaratabilirsiniz. Gethtmlsnapshot’ın görevi javascript sitenizde nasıl bir işlerlik ile çalışıyorsa bunu aynen kopya etmek.
Bizim durumumuzda, scriptimiz getresults ve updatepage gibi javascript fonksiyonlarını aynen taklit edecek. Örneğin PHP’deki DOM desteğini kullanarak sitenizin statik detaylarını yükleyebilirsiniz, ardından javascriptle ile normalde eklenecek olan içerikleri de üstüne eklersiniz. Aşağıdaki kod ile bunu yapmaya çalışacağız
// load the html page
$remote = file_get_contents('index-movies.html');
$doc = new DomDocument();
$file = $doc->loadHTML($remote);// get the _escaped_fragment_ parameter
$escapedfragment = $_GET['_escaped_fragment_'];
// NOTE: VALIDATE PARAMETERS (as always, to avoid security risks)
$params = getParams($unescapedfragment);// you can use the same php script that your JavaScript calls
$dataToAdd = include('getdata.php');// now add it to the right place in the DOM
$docToAdd = new DomDocument();
$docToAdd->loadHTML($dataToAdd['summary']);
$newNode = $doc->importNode($docToAdd->documentElement, true);
$doc->getElementById('load')->appendChild($newNode);// finally, save as HTML
echo $doc->saveHTML();
İçeriklerinizin çoğu Javascript ile oluşturulduysa
Eğer çok sayıda javascriptle yaratılmış içeriğiniz varsa, başlıksız brower(headless browser) gibi bir strateji kullanarak HTML snapshot yaratabilirsiniz. Bunun için HTMLunit denen program tam bu iş için. Htmlunit sadece java için kullanılabilecek başlıksız tarayıcı emulatörü. Standard war düzeni kullanan bir aplikasyonunuz varsa HTMLunit ve tüm ona bağlı bileşenleri WEB-INF/lib klasörüne kullanabilmek amaçlı atmanız gerekiyor. Server’ın teknolojisi java tabanlı ise, HTMLunit’i aplikasyonunuza servlet filtresi ile(daha önceki servlet filtresini reflekte edebilmek amacıyla web.xml’inizi güncellemeyi unutmayın)ekleyebilirsiniz. Servlet filtresi URL’nin içinde bir _escaped_fragment_ olup olmadığına bakacak. Eğer varsa, HTMLunit’i dahil ederek HTML snapshot yaratacak ve bunu crawlera sunacak. Kod şöyle:
public final class CrawlServlet implements Filter {
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException {
...
if ((queryString != null) && (queryString.contains("_escaped_fragment_"))) {
...
// rewrite the URL back to the original #! version
// remember to unescape any %XX characters
url_with_hash_fragment = rewriteQueryString(url_with_escaped_fragment);// use the headless browser to obtain an HTML snapshot
final WebClient webClient = new WebClient();
HtmlPage page = webClient.getPage(url_with_hash_fragment);// important! Give the headless browser enough time to execute JavaScript
// The exact time to wait may depend on your application.
webClient.waitForBackgroundJavaScript(2000);// return the snapshot
out.println(page.asXml());
} else {
try {
// not an _escaped_fragment_ URL, so move up the chain of servlet (filters)
chain.doFilter(request, response);
} catch (ServletException e) {
System.err.println("Servlet exception caught: " + e);
e.printStackTrace();
}
}
...
}
}
Bir Önceki Makalemiz : Baştan Sona Seo Tavsiyeleri
Bir Sonraki Makalemiz : Google Trends ve Arama Motoru Optimizasyonu