Indekslenebilir Ajax

Teori ve sunum
Oldukça uzun bir yazı dizisi şeklinde anlatılabilecek bir konu ancak. Ajax’ın avantajlarını kullanmak isteyen fakat optimizasyona kötü etkisinden sakınmak isteyenlerin ilgiyle okuyacağını düşündüğüm bir yazı. İlk parçada crawlerlarla server arasında nasıl bir anlaşma, nasıl bir bağ kuracağımızı açıklayacağız ve işin teorik kısmından pek ileri gitmeyeceğiz. Ne yapacağımızı tam oturtmadan ilerlersek bir yerlerde tıkanabileceğimizden bu yazıda tamemen teorik bir anlatım olacak. 2. yazıda HTML snapshot göndermek ve AJAX URL’leriyle ilgili bir yazı yazacağız. (tahmin edersiniz ki bunların ne anlama geldiğini bu yazı anlatacak)
Ajax dinamik bir şekilde içeriğin güncellenmesine imkan tanıdığı için dinamik içerik gerektiren, sık güncellenen bir site için harika ve işe yarar bir uygulama. Sorun ise bu sitelerdeki içerikleri arama motorlarının botları indekslemeye çalıştığında hepsini indeksleyememesi ile başlıyor. Göremiyor, anlamıyor, javascriptle işlenmenin ötesindeki içeriği göremiyor çünkü. Eklediğiniz içeriklerin dinamik olması kulağa hoş geliyor fakat indekslenmemesi? Arama sonuçlarındaki sonuçlar adına hiç bir yarar sağlamaması? İşte bu sorunu düzeltmek için birkaç yapılması gereken şey var. Ajax tabanlı eklentiler giderek daha çok kullanılıyor ve statik HTML sayfalarının yerine daha çok tercih ediliyor. Bu web sitesi yaratanlar için güzel bir gelişme: çünkü Ajax kullanan web siteleri içeriklerini çok daha hızlı yüklüyor ve eklentilerin hepsi içerdiği dinamizm sayesinde site kullanıcıları için çok daha kullanışlı bir site yapılmasına imkan sağlıyor.
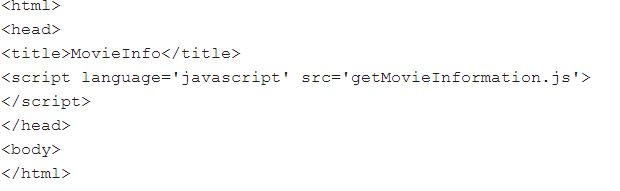
İndekslenememe sorununa geri dönersek, modern eklentiler gerçekten gelişmiş ve birçok özellik sunuyorlar fakat tam da bu yüzden indekslenme ve arama motorlarınca aranırken problemler ortaya çıkıyor. Javascriptin olduğu yerde crawler bocalıyor diyebiliriz. Örnek olarak, normal bir AJAX eklentisi crawler tarafından şuna benzer şekilde algılanıyor:
Fakat bir video olduğunda sitede bir kullanıcının ne kadar içerikle, detayla ve bilgiyle karşılaştığını hatırlayın. Hangi tarihte yayınlandığı, açıklaması vesaire birçok bilgi ve veri içeriyor bir video dosyası bile. Bir yanda görülebilir birçok içerik, detay ve bilgilendirme varken diğer yanda crawler sadece kuru bir ‘şu şöyle oldu’ diyebileceği kuru bir HTML okuyor. Peki bu fark nasıl meydana geliyor?
Browser scripti yani getmovieinformation.js elden geçiriyor ve kullanıcının gördüğü bir HTML yaratıyor, örneğin:

Browser’ın işlemesiyle oluşan fark büyük. Peki bu işlenmiş hali acaba crawlera gösterebilir miyiz? Acaba kullandığımız server bize bu konuda yardımcı olabilir mi? Bunu ileride bir daha tartışacağız.
Google bu konuda geçen senelerde bir açıklama yaptı. Ve bu açıklaması da büyük ilgi çekti. Burda önemli nokta şu: Evet, browser javascripti elden geçirip, içeriği işler hale getirebiliyor, ama crawlerlar bunu yapamıyor. Bir kullanıcının gördüğü şekliyle, javascript işlenmiş haliyle gördüğü şekilde crawlerın da görebilmesi için, sunucunun crawlera bir HTML snapshot göndermesi gerekiyor, yani Javascriptle işlenişinin ardından meydana gelen sonucu.
Yaklaşım olarak bunu izleyeceğiz, sitenin sahibinin kendi web serverının bu HTML’yi crawlera göndermesini sağlayacağız. Hem statik içerik parçalarından hem de javascript ile yaratılmış içerikleri, hepsini beraber içerecek şekilde göndereceğiz. İşte HTML snapshot dediğimiz bu.
Eğer eklediğiniz içeriklerin, crawler tarafından okunup okunmadığını merak ediyorsanız, bir browserdan sağ tıklayarak ‘view page source’ özelliğinden kontrol edebilirsiniz. View page source’da ne görünüyorsa, crawler’da ancak onu görebiliyordur. Dinamik olan içerikler buraya ilk yapıştırdığınız HTML kodundaki gibi gözükecektir. ‘Octopus’(geniş kodun içindeki açıklamadaki keywordlerden biri) diye arattığınızda sayfa kaynağının içinde hiç bir veriyle karşılaşmayacağız demektir bu.
‘İçeriklerin paralel evreni’ni yaratarak bu sorunu çözmeye çalışıyorlar web sitesi tasarımcıları. AJAX eklentilerini indekslenebilir hale getirmek için, sitenizin crawlerla yeni bir anlaşmaya varması gerekiyor:
AJAX indekslemeye sitenin de URL’lerin de uyması gerekiyor sitenin öncelikle. Dinamik olarak yaratılmış her URL için, serverınız bir HTML Snapshot sunması gerekiyor, tıpkı bir kullanıcının gördüğü sitenin halinin HTML yansımasını yani. Böyle URLler sıklıkla AJAX URLleri olarak anılıyor, ‘hash fragment’ içeren URL’ler. Örneğin www.example.com/index.html#key=value, #key=value bölümü hash fragment olarak adlandırılıyor.
Arama motoru HTML snapshotı indeksliyor ve orjinal AJAX URLlerini arama sonuçlarında bu işlem sayesinde gösterebiliyor.
Çözüm?
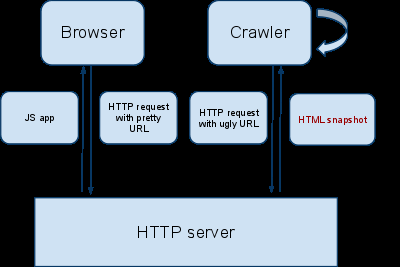
Siteniz öncelikle AJAX indeksleme şemasına(yukarıdaki) uymaya başlıyor. Her dinamik olarak işlenen içerikli URL için sunucunuz sitenin tarayıcı ile görünen şeklini, yani HTML snapshotını yolluyor. Böyle URLler genelde, içinde hash fragment barındıran URLler oluyor örneğin, www.example.com/index.html#key=value, #key=value dediğmiz kısım da ‘hash fragment’ kısmı. Ardından arama motoru HTML snapshot’ı indeksliyor ve AJAX URLnizi arama sonuçlarında sunuyor.
Bunun olabilmesi için eklentiniz içinde AJAX URLnizin içinde özel bir ‘dizim’ kullanmanız gerekiyor. Crawlerlar geçici olarak bu AJAX URLlerini kendince modifiye eder ve sunucudan talepte bulunur. Bu modifiye edilmiş URL’ler sunucuya browsera gönderdiği doğal web sayfasını değil, HTML snapshot göndermesini gerektiğini ifade eder. Modifiye edilmiş URL ile ilgili içeriği crawler edindiğinde, içeriği indeksler ve modifiye edilmemiş URL’yi arama sonuçlarında gösterir. Sonuç olarak son kullanıcılar her zaman hash fragment içeren URLleri yani modifiye edilmemiş URL’leri ve yine başka deyişle AJAX URLlerini görür.
Başlangıç:
Öncelikle crawlera sitenizin Ajax indekslenme şemasını desteklediğini belirtmemiz gerekiyor. Gayet basit. Hash fragmentlarınızın içersine küçük yerleştirmeler yapıyoruz. Hash fragmentlerimizi ünlem ile başlatıyoruz.
Şöyle olan bir linki,
www.example.com/ajax.html#key=value
şu hale getirmemiz gerekiyor.
www.example.com/ajax.html#!key=value
Siteniz bu şemaya uyum sağladığında, artık Indekslenebilir Ajax düzenine uygun hale gelecek. Siteniz HTML snapshot ile arama motorlarını besleyebildiği sürece crawlerlar içeriği okuyabilecek anlamına geliyor bu da.
2. işlem: içinde _escaped_fragment_ bulunan URLlerden gelen talepleri desteklemesi için sunucuyu ayarlamak
Örneğin, get www.example.com/index.html#!key=value URLnizin indekslenmesini istiyorsunuz. Crawler ile anlaşmanız gereği, bu URLnin bir HTML snapshotını crawlera sağlamanız gerekiyordu ki böylece crawler siteyi görebilsin. Peki server normal bir web sayfası yerine HTML snapshot göndermesi gerektiğini nereden bilecek? Cevap, crawler tarafından istenen URLyi crawler AJAX URL haline getirecek,
örneğin
www.example.com/ajax.html#!key=value
‘i alacak ve kısa bir süreliğine:
www.example.com/ajax.html?_escaped_fragment_=key=value ‘a dönüştürecek
Tabii niye buna gerek var, bu soru aklınıza gelebilir. İki önemli neden var böyle olmasının altında.
Hash fragmentler hiç bir zaman sunucuya HTTP talebinin bir parçası olarak gönderilmez, başka deyişle, crawlerlar serverın onun www.example.com/ajax.html#!key=value için içerik istediğini belli etmenin bir yolunu arar. Server ise diğer yandan, bir sayfa yerine bir HTML snapshot göndermek zorunda olduğunu bilir, javascriptlerle işlenmiş sayfayı göndermeyi ister.
Not: Crawlerlar fragment’taki bazı karakterleri görmezden gelebilir dönüştürme esnasında. Orjinal fragment’a sahip olabilmek için, tüm %XX karakterlerini fragmentteki ‘unescape’ ettiğinize emin olun. Daha açık olmak gerekirse %26 & haline gelmedi, %20 boşluk olmalı, %23 #, %25 % olmalı… vesaire.
Şimdi orjinal URLnize yeniden sahipsiniz ve crawlerın hangi içerik talebinde olduğunun. Artık yapmanız gereken HTML snapshot yaratmak. Nasıl yapmalı? Birçok yolu var, işte onlardan birkaçı:
Headless Browser
Javascriptle gerçekten çok sayıda içeriğiniz işleniyorsa, headless browser örneğin HTMLUnit denen programı kullanabilirsiniz HTML snapshot kullanabilirsiniz. Crawljax watij.com gibi araçları da kullanabilirsiniz.
PHP ve ASP.Net için
Server yanlı teknolojilere dayanan birçok içeriğiniz varsa PHP veya ASP.Net gibi, mevcut olan kodunuzu aynen alıp, sitenizin javascript parçacıklarını ve statik, server yanlı yaratılan HTMLler ile kullanabilirsiniz.
Eklentiler ile HTML Snapshot
Web sitenizin statik bir versiyonunu online olarak da yaratabilirsiniz. Birçok eklenti bir veri tabanından verileri alır browser tarafından da bu veriler işlenir. Bunun yerine, ayrı bir her AJAX URLsi için ayrı bir HTML sayfası yaratabilirsiniz.
Önerileri değil kendi belirlediğiniz HTML snapshot mekanizmasını kullanın.Headless browser mutlaka aplikasyonunuzun içeriğini doğru şekilde işlediğinden öncelikle emin olun.
Buraya kadar teoriyi oturttuğumuzu düşünüyorum. HTML snapshot, AJAX URL terimler açıklığa kavuştu, şemalarla destek sağlandı. Diğer yazı, AJAX’ı crawlera okunur hale getirmek için küçük birkaç detay ve HTML snapshot göndermek üzere olacak.
Bir Önceki Makalemiz : .Htaccess kullanımı ve güvenlik
Bir Sonraki Makalemiz : Baştan Sona Seo Tavsiyeleri




